

According to a 2020 survey of 600 senior executives conducted by Harvard Business Review, 55% of organizations agreed that data analytics for decision making is extremely important and 92% asserted data analytics for decision making will be even more important in two years. Organizations that strategically deploy tools across their finance and accounting functions have an opportunity to better structure manual processes into more stable, accurate, repeatable, and readily auditable procedures (see Gregory Kogan, Nathan Myers, Daniel J. Gaydon, and Douglas M. Boyle, “Advancing Digital Transformation,” Strategic Finance, December 2021). Thus, financial decision makers are increasingly expected to engage data analytics to enhance decision making and create more efficient processes.
An introduction to the basics of data analytics is the first step for those wanting to deploy specific technologies, create efficiencies in business decision making, and stay current with evolving technologies. There are many analytical methods (e.g., clustering, classification, and regression). While each has specific data requirements, they all share some common activities, such as understanding the business problem being analyzed, identifying data sources, and understanding basic features about the data. Learning the fundamental context of data analytics leads to success in the implementation of specific technologies.
On the other hand, a lack of understanding in data analytics and its value can result in organizational resistance to change and cause organizations to fall behind the evolving market. In “Will We Ever Give Up Our Beloved Excel?” (Management Accounting Quarterly, Winter 2020), Jennifer Riley, Kimberly Swanson Church, and Pamela J. Schmidt addressed Microsoft Excel’s inability to hold the magnitude of data now accessible through data analytics and examined the resistance to changing technologies. The results of their study confirmed that respondents recognize the value of switching to data analytics tools regardless of the costs. Additionally, they found the costs of switching increase the resistance to change, while perceived value decreases the influence to resistance to such a change. Educating professionals on the basic concepts of data analytics could help them understand the value and decrease the barriers to implementation.
This is where understanding the phases of Cross-Industry Standard Process for Data Mining (CRISP-DM) can assist. Developed by a team of experienced data mining engineers in the late 1990s, CRISP-DM has been the most widely used data analytics method for more than 20 years. Its development was driven by the desire to establish a universally accepted data mining methodology, and it provides a fundamental understanding of data analytics. With this foundation, management accounting and finance professionals will be better able to approach more complex data analytics implementations and better understand the latest developments in specific technologies.
Data analytics projects work best when a systematic and repeatable process is followed for transforming raw data into actionable information. Following the CRISP-DM framework (see Figure 1) is like using checklists to ensure all required activities have been performed. CRISP-DM is made up of six iterative phases (see Table 1):
1. Business understanding
2. Data understanding
3. Data preparation
4. Modeling
5. Evaluation
6. Deployment/communication
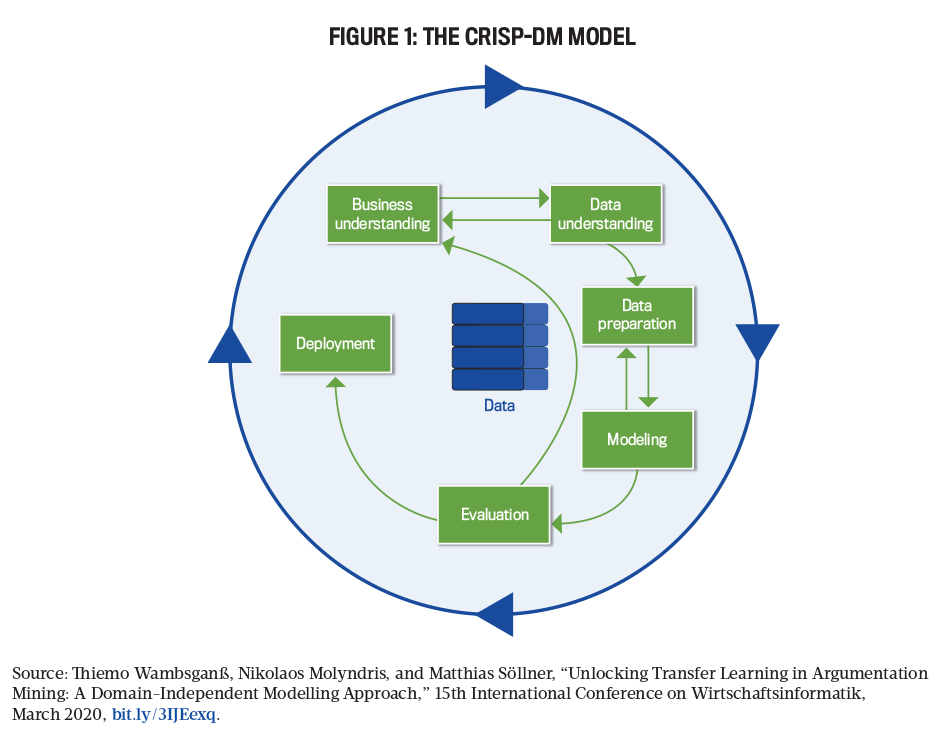
It’s very important to assign responsibilities to team members (e.g., business analysts establish requirements, IT specialists gather required data, and data scientists develop and test advanced modeling techniques) with the requisite skills that vary among the phases. Let’s take a look at each phase.
PHASE 1: BUSINESS UNDERSTANDING
The first phase of CRISP-DM is developing a solid understanding of the business problem. During this phase, business analysts meet with the client to outline the project objectives and requirements in terms that a broad audience of business users can understand. Examples of problems that data analytics can solve include determining the adequacy of loan loss reserve or effectively assessing the conformance to internal control policies.
Once the broad outline of objectives and requirements is agreed upon, the analysts translate the objective and requirements into project goals. Examples of goals include “reduce loan losses by 10% in three years by attracting more credit-worthy customers” or “reduce purchasing fraud by 5% within one year by developing a model that can detect potentially fraudulent transactions in real time.” Goals should be tailored to organizational needs and mirror the organizational objective. After the objectives and goals are determined, the analyst develops an initial plan for achieving the goals.

PHASE 2: DATA UNDERSTANDING
During the second phase of CRISP-DM, business and data analysts obtain a detailed understanding of the project’s data needs. This phase begins by reviewing the business questions identified in phase 1 and documenting the data requirements. Data can come from internal sources such as the enterprise resource planning (ERP) system or general ledger or from external sources like industry benchmarking statistics.
Data understanding has three main objectives: determining the data format, determining the data type, and profiling the data. Typical tasks in the second phase of CRISP-DM include collecting the data; exploring the data; describing the data; and ensuring the data quality, accuracy, and validity. It’s important to ask many questions about the data during each of the tasks in data understanding in order to obtain a full view of the information and to allow for better interpretation. Some sample questions that can help you better understand the data include:
Collecting the data:
- Where will we get the data? From internal or external sources?
- Who is responsible for obtaining the data?
Describing the data:
- How large is the data (e.g., how many columns and rows does the file contain)?
- What is the format of the data (structured, semi-structured, or unstructured)?
- What types of data are in each column? Are they qualitative (nominal or original) or quantitative (interval or ratio)?
Exploring the data:
- What are the “typical” values in each column? (For instance, quantitative variables can use average, minimum, or maximum values. Qualitative variables look at the frequency of occurrence of a value.)
- Are there anomalies or outliers?
- Are there missing data points? If so, is it possible to make adjustments to continue (e.g., exclude the entire record or impute a value based on values in other columns)?
Verifying the data quality:
- Is the data accurate?
- Is the data valid (i.e., conforms to business rules; e.g., invoice date must be on or after the sales invoice date)?

One important area to consider is data structure. Data comes in several different formats, including structured, semi-structured, and unstructured data. Structured data is highly organized with well-defined data types, such as a database table. Semi-structured data has some organization but isn’t fully organized and thus isn’t ready to be inserted into a relational database. This data is unformatted or loosely formatted numbers or characters inside a field with little or no structure within the field. An example of this could be a social media post. Finally, unstructured data is data that has no uniform structure and typically isn’t text-based, for example, image or sound files. This data can be difficult to manage because it might be voluminous, difficult to catalog or index, and problematic to store.
Another crucial area of understanding is the data type. There are a number of different types, including nominal, ordinal, interval, and ratio. The type of data collected and used determines both the types of analytics that can be performed (e.g., regression for numeric data or clustering for nominal data) as well as the types of graphs that can be used to communicate results (e.g., line charts for ratio data or bar charts for nominal data).
Nominal data includes names, labels, or categories. This data can’t be ranked or ordered. Ordinal data is categorical data that can be ranked or ordered regarding preference or in relation to another. Examples include hot vs. cold or good vs. bad. These two opposites can have rankings in between the two extremes, but all rankings may not be equal in relative distance between each increment. Interval data can measure distances and spans, but there’s no zero reference. Ratio data has an absolute zero in relation to the data type, and the measurement and intervals between numbers are meaningful.
In a data analytics problem, there can be a combination of different types of data (qualitative or quantitative). For instance, a survey can gather categorical information such as gender and quantitative information such as salary. Collecting diversified data allows analysts to solve different questions and provides a broader basis to analyze.
At the completion of the data understanding phase, it’s very helpful to document the data sources and data prescriptions. A data lineage report identifies each data element and the primary source for that data element. A data dictionary lists key items relevant to each data field. Some of the items that can be defined include:
- Table name: the name of the database table/spreadsheet tab that holds the data
- Column name: a quick identification or title for the data collected for each variable
- Description: a short description of the data held in this column
- Data type: identifies how the data is measured, i.e., whether it involves qualitative (nominal or ordinal) or quantitative (interval or ratio) scales
- Unit of measurement: for numeric data, identifies the unit of measurement (e.g., U.S. dollars, euros)
- Allowable range of values: describes the range of values as dictated by business rules (e.g., purchase order date is before date of receiving report)
PHASE 3: DATA PREPERATION
Most data sets are imperfect and need to be revised to ensure the data models are fed with consistent, high-quality data. In phase 3 data analysts and data scientists transform raw data from transactional data sources and store the data in an analytics data warehouse that will be the primary data source of the data models. Phase 3 includes selecting, cleaning, constructing, integrating (merging), and formatting the data (see Table 2).
To accomplish each of these objectives, it’s helpful to review the extract, transform, and load (ETL) process, which transforms raw data into a consistent format and loads it into a centralized data repository (e.g., data warehouse). Data scientists use the data from this data repository when they develop, test, and evaluate the various analytic models being considered (e.g., a clustering model that identifies customers who are likely to default on their loans).
Figure 2 illustrates the ETL process. The extract step involves extracting the data from a transactional data source, such as ERP systems or company budgets on spreadsheets, and then storing a copy of the raw data into a data staging area. In the transform step, the data is appropriately formatted in accordance with the analytical data warehouse specifications, such as data cleaning (remove duplicates, eliminate noisy data, etc.), data transformation (normalize data, create discrete categories for numeric data, and create new data columns), and data reduction (sampling, eliminating nonessential columns from a spreadsheet, and so forth). Finally, in the load step, the transformed data is loaded from the staging area into the analytical data warehouse. All analysis performed (e.g., statistical modeling or ad hoc analysis) uses data from the data warehouse as opposed to taking it directly from transaction sources. This reduces the chance that the transaction-source databases become corrupted.
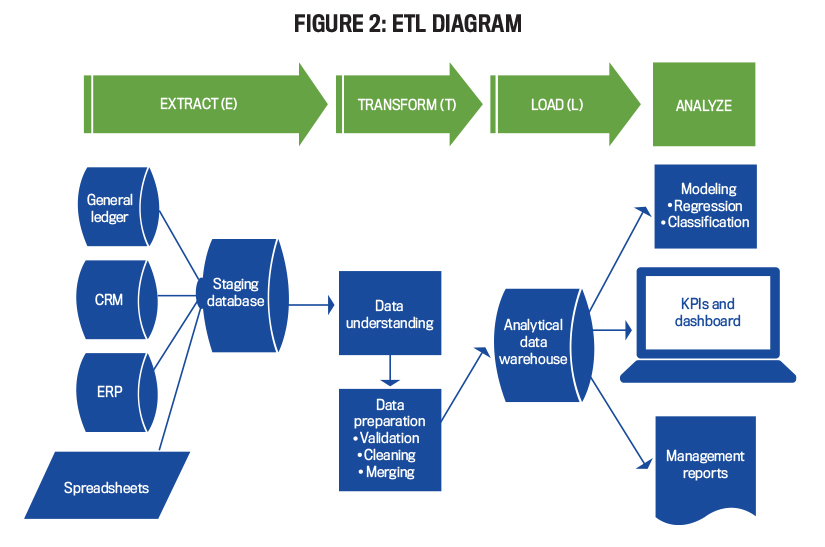
To be sure that the process is complete, it’s important to look at the five dimensions of data quality as outlined by Lorraine Fellows and Mike Fleckenstein in their 2018 book, Modern Data Strategies: accuracy, completeness, consistency, latency, and reasonableness. Accuracy is the correctness of data. Completeness ensures the data set includes all necessary elements. Consistency refers to the representation and interpretation of the data. Latency refers to the timeliness of data availability. Finally, reasonableness is the credibility, quality, and accuracy of the data set.
PHASE 4: MODELING
Phase 4 involves experimenting with many analytics models, such as regression or decision trees, to identify interesting patterns in the data. This phase includes selecting and applying appropriate modeling techniques to generate training and test data sets, building various models, and assessing the model. There are four data
analysis types:
1. Descriptive analysis provides information on what happened. An example would be “What has been our historical trends in lost customers?”
2. Diagnostic analysis provides information on why something happened, answering questions like “Why have customer losses been increasing?”
3. Predictive analysis provides information on what’s likely to happen, such as “Which customers are likely to leave?”
4. Prescriptive analysis provides information on how processes and systems can be optimized. It answers questions like “Which customer should we contact to increase the chance of retaining them?”
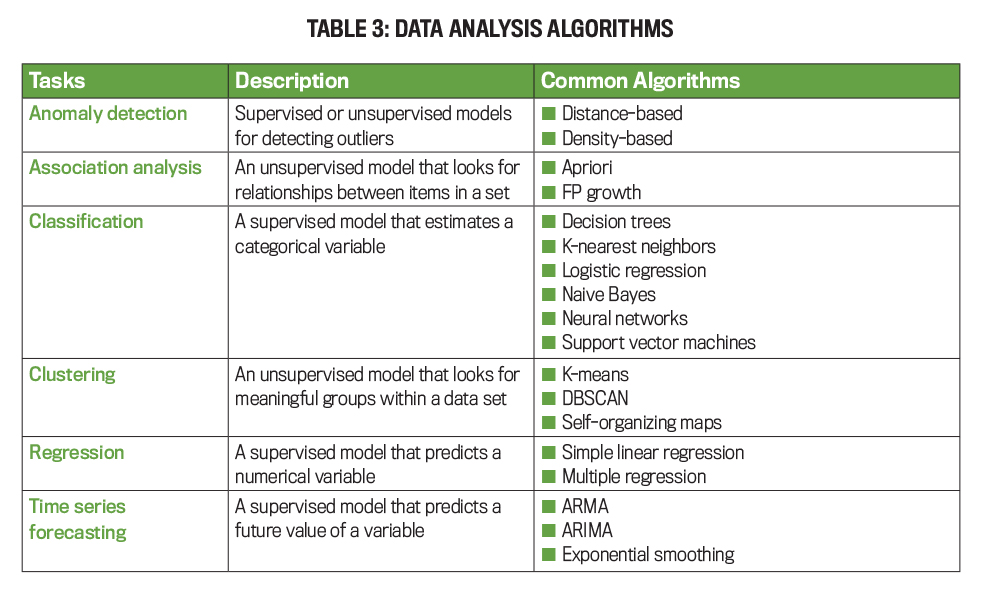
The most appropriate type of data analysis will be determined by the business problem the company is aiming to solve. Table 3 outlines the most common data analysis tasks and algorithms used to accomplish the data analysis task.
PHASE 5: EVALUATION
During the fifth phase, the data scientist and business analysts compare the results of the different models developed during phase 4. The typical tasks for phase 5 include evaluating model results, reviewing the process, and determining the next steps. When evaluating a model, the following questions need to be considered:
- How well does the model perform? Are the results better than random guessing?
- Do the results of the model make sense in the context of the business problem being analyzed?
- Is this the simplest model?
- Can the results be easily interpreted and explained?
- Is the model cost-effective?
- Do the results of the model make sense in the context of the problem domain?
PHASE 6: DEPLOYMENT
Once new information has been discovered, it must be organized and presented in a way that the audience can understand and use. Depending on the requirements, this step can be as simple as generating a report or as complex as deploying a new computer system. The typical tasks for phase 6 include plan deployment, plan monitoring and maintenance, producing a final report, and reviewing the project.
Plan deployment and plan monitoring should be in direct response to insights gained by the outputs of the model. The model should appropriately convey information about the data set, and the plan should be addressing the business problem.
Data visualizations can improve users’ ability to understanding complex data. According to the IMA® (Institute of Management Accountants) report Data Visualization,data visualization can be used to provide insights in a memorable fashion. It is effective when it can convey a story, and memorable stories will make it easier for the audience to connect and remember the information being conveyed. Relatable stories lead to emotional coupling. Both the storyteller and the audience can relate to the same experience. Research shows that storytelling can engage parts of the brain that lead to action. Good storytelling allows individuals to properly review the project and understand how the data analytics process has substantially addressed the business problem.

A SOLID FOUNDATION
Using data analytics effectively starts with knowing how to ask good questions and a strong understanding of the fundamentals of the data analytics process. CRISP-DM is the most-used framework and systematically addresses business problems in a step-by-step process that goes from business problem to business solution. This includes the business problem, the data, the preparation of the data, the modeling, the evaluation, and the deployment.
Accounting and finance professionals who are educated in the basics of data analytics are better equipped to approach complex data analytics implementations into their organizations, are better able to understand the latest developments in specific technologies, and can become leaders in the data analytics frontier of their organization. When they’re able to change the way they think about a problem, they can also change the way they approach the solution. Thus, it’s important that those given the responsibilities of these projects have a sound understanding of the phases in the information processing of data.
The more informed individuals are in data analytics, the more likely data analytics will be used effectively and efficiently. Individuals who have a data analytics mindset are informed and can lead their organization with data analytics projects, allowing the organization to implement effective change and foster growth in the organization and in the application of data analytics.

February 2023

