

Driven by the rapid growth in computer processing capability and in both internal and external unstructured data, textual analysis is now used in accounting and auditing settings. It allows accountants to identify key terms in lease agreements and to track customer contracts for revenue recognition purposes, auditors to review journal entry descriptions, and investors to compare management discussion and analysis (MD&A) between companies.
Textual analysis is especially important today due to the increased emphasis in accounting on unstructured data, which includes not only documents but also emails, text messages, logs and notifications, video and audio files, and still images. Textual analysis allows accountants and auditors to analyze this data and use it to drive decision making. Further, textual analysis provides accountants with additional knowledge beyond quantitative data, including insight into complex models of human thought and language use.
Nothing’s perfect, however. Textual analysis has some drawbacks, as it can be time-consuming and users need to be careful not to jump to conclusions too rapidly with their interpretations. In addition, its iterative process may be frustrating at times, especially for inexperienced users. There may be software issues as well.
KEY CONCEPTS OF TEXTUAL ANALYSIS
Textual analysis is an iterative process involving several concepts. Before getting started, however, accountants and auditors should be familiar with the following textual analysis concepts: word count, concordance, word cloud, word search, word trees, collocation, fog index/readability, and sentiment analysis (tone). Let’s take a closer look at each of these.
Word count: Word count is a method that totals the number of words in a document or a sentence. Most sentences in accounting documents include between 20 and 25 words. Sentences longer than this will therefore lower the document’s readability score. Worse, some analysts may suspect that the level of verbosity in certain documents represents the company’s attempt to hide something.
Word count can also tally how many times a specific word appears within the document. For example, if Company A uses the word “loss” 40 times in its annual report, and a competitor, Company B, uses it 15 times, someone may question whether Company A is worse off than Company B.
Concordance: Related to word count, a concordance is a list of the frequency of all words in a document along with the immediate words surrounding each word. Thus, a concordance provides context for the word occurrences, which enables greater insight into how a word is used in the document. Textual analysis software can also count the number of pages, paragraphs, and lines in the text. Most software also displays the number of characters, either including or excluding spaces.
Word cloud: Word clouds are graphical representations of word frequency. Words that appear more often in the source text appear bigger and bolder in the word cloud, which can be used to communicate the most salient points or themes in the text. For example, a company that makes sporting goods might use a word cloud to analyze customer reviews of running shoes to visually display the specific words used by customers and thereby determine what is most important to them.
Word search: Given the iterative nature of textual analysis, it may involve multiple word searches. For example, a word count may suggest that the term “risks” is used in the MD&A section of an annual report multiple times. The user may then search this section for each occurrence of “risks” to look for clues regarding the types of risks discussed.
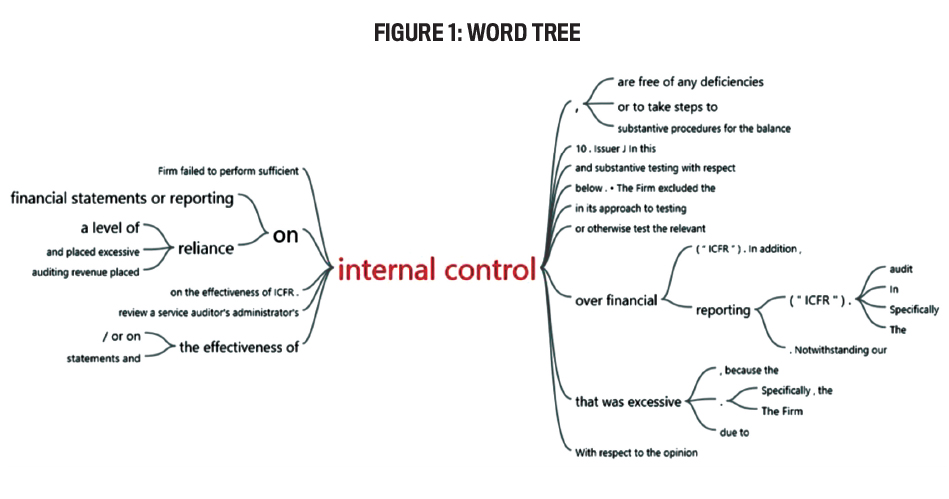
Word trees: Word trees are a visual representation of a set of words, using a branching structure to illustrate relationships between words. Thus, words that are more commonly used within a document are given a “tree,” and each “branch” represents words that are associated with the “tree” word. This gives users an idea of the connotation each word has within the documents.
Word trees can help users to better interpret word meanings within the document without having to read the entire document. In Figure 1, for example, the main term, “internal control,” has multiple phrases or words that appear immediately before or after it in the document. As with a word cloud, the bigger and bolder the word or phrase that precedes or follows the main term appears, the more often that word or phrase is used in the document. A word tree is a visual concordance.
Collocation: Certain words are often set in close proximity, or collocated, to each other. For example, consider the terms “financial” and “statement.” Several textual analysis packages will identify collocated words like this without user intervention. In accounting, identifying common collocated words, such as “long-term debt,” “marketable securities,” and “fixed asset,” is helpful in determining the text’s meaning.
Fog index/readability: As the term implies, fog index (or readability) measures how difficult text is to understand. The fog index is a linear combination of average sentence length and proportion of complex words, with complex words being defined as those with more than two syllables. There are two standard readability tests: Flesch Reading Ease and Flesch-Kincaid Grade Level. Both tests use the same core word length and sentence length measures, but each test uses different weighting factors. The results of the two tests correlate inversely—that is, text with a comparatively high score on Reading Ease will have a lower score on the Grade Level test.
Recent accounting research has shown that the fog index isn’t a good measure of financial statement readability given that many terms used in business texts are complex words that are generally familiar to investors and analysts. For example, consider common financial statement words such as “contingency,” “deviations,” “preliminary,” “probable,” and “recalculate.” To address this issue, accounting professors Tim Loughran and Bill McDonald suggest that, for business texts, simply using document length or file size is a more efficient and effective proxy for conventional readability indices.
Sentiment analysis (tone): Sentiment analysis focuses on the specific tone or emotions expressed in a document. There are two types of sentiment analysis: One is focused on the polarity of documents (positive, negative, or neutral), the other on more specific emotions (uncertainty, litigiousness, etc.). Net sentiment analysis identifies words in a document as either positive or negative in tone and then calculates a net difference. The difference can either be positive (more positive words than negative), negative (more negative words than positive), or neutral (an equal number of positive vs. negative words).
Sentiment analysis focused on the detection of specific emotions in text uses specific word lists (where the words are considered indicative of the emotion of interest) as filters. The specific word list is input to the software tool used for the analysis and is employed to identify the occurrences of the words on the list. If a high number of words in the list appear in the accounting document, then the overall tone of the report can be determined based on the sentiment word list that was used. For example, if an uncertainty word list was used and textual analysis indicates that the document examined has a high number of uncertainty words, then the textual analysis would suggest that the document had an ambiguous tone. For financial information, sentiment analysis often uses the Loughran and McDonald Sentiment Word List to identify overall tone of a document.
THREE KEY METHODS
Textual analysis software is driven by several types of methods, the most common of which are machine learning, natural language processing (NLP), and network analysis.
Machine learning: Machine learning uses AI to train computers to look for patterns that can be used in accounting. With machine learning, the textual analysis software checks for word counts, uses word trees to connect common words, and runs a fog index to get the overall tone of the document. Machine learning is instrumental in the success of textual analysis and can help the accounting field to evolve.
Natural language processing: NLP builds on machine learning and pulls meaning from unstructured data. It’s often used to translate accounting documents from one language to another. NLP can also summarize documents so that investors can read them more quickly and easily.
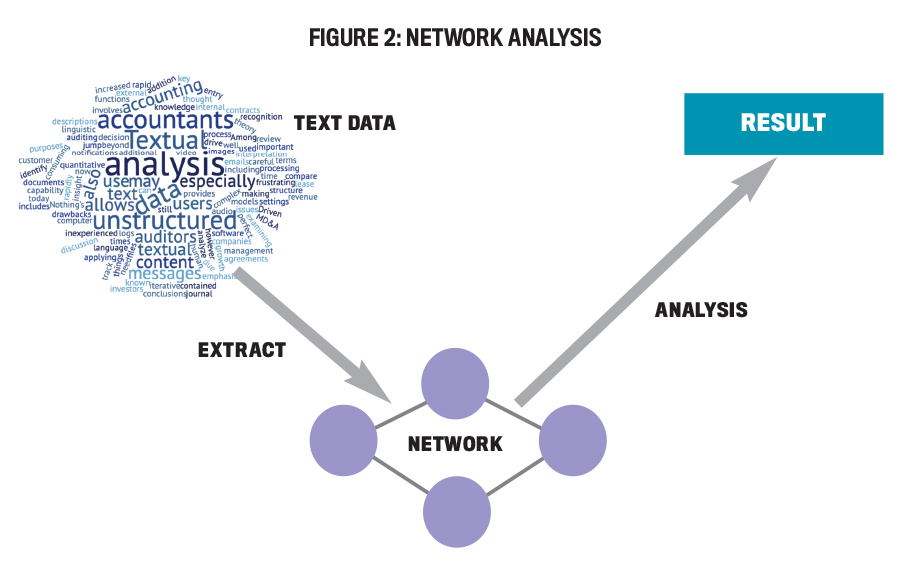
Network analysis: Network analysis finds connections between different types of data. Specifically with textual analysis, this method is implemented with word trees to accurately group different texts into what’s referred to as “notes.” The notes are included in images to demonstrate how they’re connected to one another based on words they have in common. Figure 2 shows an example of how network analysis can help to improve textual analysis by making it easier to scrutinize text. Within the accounting field, network analysis can be used to connect different types of company reports (10-Ks, 10-Qs, annual reports, and so on) to one another based on the keywords in each document.
Click to enlarge.
ACCOUNTING AND AUDITING APPLICATIONS
Accountants and auditors use textual analysis in several areas, and its use is expected to increase significantly in the coming years. With that in mind, here are some of the areas in which textual analysis can provide a value-added approach to routine business and compliance functions.
Contract analysis: KPMG manages client contracts using its proprietary Cognitive Contract Management system. Contract data is loaded into the system, which analyzes each contract to identify key terms to save KPMG time and money. Similarly, Deloitte uses a proprietary software called dTrax, which blends AI and machine learning to examine and manage contract portfolios. This process saves Deloitte significant hours and costs as it evaluates contract pricing, service offerings, and staffing support. (For more, see “Real-World Uses of Textual Analysis” at the end of the article.)
Lease accounting: Financial Accounting Standards Board (FASB) Accounting Standards Codification (ASC) Topic 842, Leases, requires many companies to record an asset and liability on the balance sheet for most leases. To avoid misstating the balance sheet, companies need to ensure that they have identified and reviewed contracts for all embedded leases. Many companies now use textual analysis to handle these tasks.
Revenue recognition: The new revenue recognition standard, ASC 606, Revenue from Contracts with Customers, requires companies to examine customer contracts. Many large companies and their external auditors use textual analysis to identify unique contract features, such as contract length, payment terms, risk, and timing, as well as amount of future cash flows, payment obligations, and payment dates.
General ledger journal entries: Auditors may use textual analysis to review general ledger journal entries to look for high-risk entries. For instance, EY Helix has analyzed more than 580 billion lines of journal entry descriptions in the past 12 months. These journal entry descriptions may identify red flag transactions that require further investigation, such as manual entries made late in the fiscal period.
Footnote disclosures: Auditors often rely on textual analysis to examine client footnote disclosures. For example, one large audit firm has used textual analysis to identify key components of publicly traded company footnotes by industry. The firm compares the footnote disclosures of each client to the information in its disclosure database, looking for discrepancies that may warrant further investigation.
Management discussion and analysis: MD&A provides investors with information about a company’s past performance, future goals, and new projects. For investors and analysts evaluating multiple companies, textual analysis can help monitor and organize this information.
Monitoring social media sentiment: Today, organizations need to continually monitor their social media presence, as one poorly timed negative social media incident can significantly impact an organization’s reputation and even have financial implications. As a result, several organizations are turning to textual analysis to monitor social media and identify potentially harmful posts.
Privacy compliance: Recently, organizations have spent significant time complying with data privacy regulations, including the European Union’s General Data Protection Regulation and the California Consumer Privacy Act. Textual analysis can assist organizations by identifying all impacted data for review to ensure compliance with privacy regulations.
Video recordings of interviews: During the COVID-19 pandemic, auditors replaced face-to-face inquiries with video conferences. In general, the content of video conference interviews can be recorded and transcribed easier than a face-to-face inquiry. Using textual analysis software, auditors can examine these transcripts for indicators of potential fraud, phrases such as “write-off” or “failed investment.”
TEXTUAL ANALYSIS SOFTWARE
Unlike graphical representation software, where Tableau and Power BI are now widely used, most textual analysis software remains proprietary. Organizations that we spoke with indicated that developing textual analysis software internally helped them obtain a competitive advantage in this fast-growing field.
But your company doesn’t necessarily have to create its own software to benefit from textual analysis. Here are some details on two free textual analysis software packages: AntConc and RapidMiner.
AntConc specializes in analyzing text to find different patterns. As with any textual analytics program, users start by converting all documents into text files and uploading the files to the AntConc software. One challenge in using AntConc is that words need to be typed in one by one instead of loading a list of words. For example, the 2017 annual reports of Sears and Target can be compared by using the Loughran and McDonald Sentiment Word List for the words pertaining to “uncertainty.” Consider the word “risks,” for example. The 2017 Sears annual report used the word “risks” 24 times, while the Target annual report included it only 14 times. To give the reader some context, the analysis also shows the sentences in which the word “risks” appears (see Figure 3).
Click to enlarge.

We also ran an analysis for the word “uncertainties.” In the Sears annual report, “uncertainties” is used seven times, whereas the Target annual report included it only three times. While this needs further investigation, the AntConc results therefore suggest that Sears had a greater number of uncertainty words within its 2017 annual report than Target. This could signal a higher potential of fraud and would thus require further investigation.
Compared with AntConc, RapidMiner is more advanced, as it includes both machine learning and predictive analytics and requires a textual analysis extension in order to perform textual analysis, including the use of the Loughran and McDonald Uncertainty Word List for the uncertainty sentiment analysis.
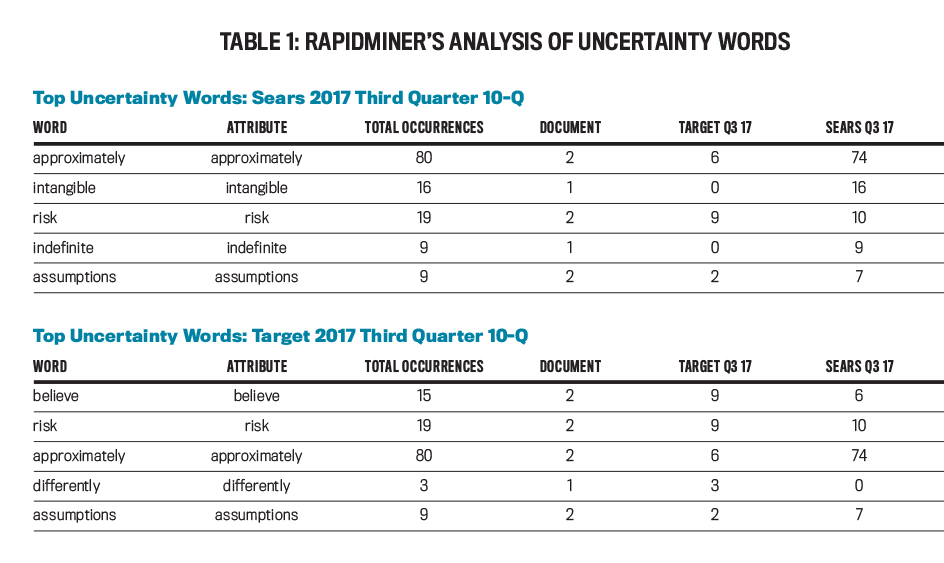
Unlike AntConc, RapidMiner allows users to upload word lists rather than single words. We used RapidMiner to analyze the 2017 Sears and Target accounting documents, using the third-quarter 10-Q (see Table 1). Sears had many more uncertainty words when compared to Target. The highest number of repetitive uncertainty words was 74 for the word “approximately” in the Sears 10-Q, while the highest number in the Target 10-Q was nine for “believe.”
Click to enlarge.
While AntConc and RapidMiner both identified differences between Sears and Target, each has its own pros and cons. The AntConc software is easier to navigate and doesn’t require users to download a textual analysis extension. Further, AntConc provides a sentence preview so users can see how each word is used within the accounting document.
Although more difficult to navigate, RapidMiner offers a much more extensive search. And, as mentioned earlier, it also allows users to search by multiple words by loading in a word list vs. one word at a time with AntConc. Both systems, however, have similar outputs.
WHAT IT MEANS TO YOU
With technology now providing the means to analyze unstructured data more quickly and efficiently, becoming adept with textual analysis is an important skill for accountants and auditors to master. As the volume of unstructured data continues to grow, textual analysis can enable your organization to glean many interesting and useful insights to reduce risk, improve performance, and, in the process, remain a step ahead of the competition.
Simply put, if you’re a management accountant or financial professional with a line to the C-suite, now is the time to lay the groundwork for an “all-in” approach to this value-added technology.
Real-World Uses of Textual Analysis
Deloitte
Deloitte’s dTrax, which uses AI and machine learning to examine and manage contract portfolios, can be customized to fit clients’ needs. Partnering with OpenText technologies, Deloitte is developing data solutions for the utilities, oil and gas, and food service industries.
EY
EY developed Forensic Data Analytics for clients’ compliance with the EU’s General Data Protection Regulation. EY’s goal is to identify data patterns from multiple data sources that need closer attention for compliance monitoring. EY also developed EY Helix, a global audit analytics tool, to analyze journal entry descriptions.
KPMG
KPMG developed its Cognitive Contract Management system for clients to analyze contracts. KPMG says the system will help organizations address commercial leakage, clause compliance, and contract pricing comparisons, as well as internal audit, legal department, and supplier performance issues. KPMG also advertises an Intelligent Underwriting Engine that uses textual analysis to identify underwriting risks through contract review.
PwC
PwC claims to have made a significant investment in natural language processing for supply chain management applications, to increase transparency, improve planning, and enhance logistics flows.
BDO
BDO uses textual analysis to examine large amounts of unstructured customer data in order to assist clients in complying with the California Consumer Privacy Act and other data privacy and protection principles. The company has also partnered with Brainspace to develop textual analytics applications, including those that will assist in fraud investigations, support litigation, due diligence, and risk assessments.
Crowe LLP
Crowe uses textual analysis for insurance claims clients. The company says its application examines interview notes, adjuster case commentaries, medical reports, and similar text-based formats. Crowe recently partnered with NICE Actimize to develop applications that can identify financial service industry crime.
Grant Thornton
Grant Thornton offers Ephesoft Smart Capture solutions to help clients evaluate unstructured data specifically related to back-end processes, such as invoicing, accounts payable, and contract management. Grant Thornton has developed cognitive automation to leverage structured, semi-structured, and unstructured data for tax applications. The company claims this technology recognizes voice, images, fuzzy logic, and other unstructured tax data.
RSM
RSM uses textual analysis in forensic data analytics to combine information from multiple sources. The company claims its application will help investigators quickly identify big-picture discrepancies and connect the dots in fraud cases.

June 2021

